A schema is a distinct namespace to facilitate the separation, management, and ownership of database objects
The use of schemas can help to combine entities from separate applications or functional areas, or logical groups, into a single physical database.
One example of relevance is the protection of database objects in application development environments where developers and testers share the same set of database objects
Table 'Crawler_Status' in the database CMS can be used by two different users as follows
Table1, CMS.Testing.Crawler_Status is used by testing team
Table2 , CMS.Production.Crawler_Status is used by production team
Note : Usually we use two different databases
Performance
Always refer to the database objects(Table names , Views) using a fully qualified name. At the very least, use the schema name followed by the object name, separated by a period (.)
Example
SELECT COL1 , COL2 FROM DBO.TABLE_NAME
It will take less processing time for the Database Engine to resolve object names
Otherwise database engine checks in master database,if it’s not there in master database it checks in the current session database depends on schema
Security
Use schemas to protect the base database object from being altered or removed from the database schema by users without sysadmin permissions.
User permissions should be managed at the schema level
Tuesday, September 14, 2010
Tuesday, June 8, 2010
Bulk Import
Points to remember when Bulk-Loading Data
We use different Import mechanisms (BCP , Bulk Insert or SSIS) to bulk-load data , we should consider the following factors to get top performance
1.Disable indexes and Bulk-load data
The best scenario is bulk- loading data into an empty heap ( a table with no indexes )
Disable indexes before Bulk-load and rebuild indexes once the Bulk-Load completed.
2.Bulk-logged Recovery Model
Change recovery mode from FULL to Bulk-Logged lets database perform minimal logging during the data load.
Data that is loaded during a bulk load usually has no need for the point-in-time recovery capability of the full recovery model.
Decreasing the volume of log writes improves performance.
Note: Recovery models - Full [Default Recovery Model] ,
Bulk Logged and
Simple
We use different Import mechanisms (BCP , Bulk Insert or SSIS) to bulk-load data , we should consider the following factors to get top performance
1.Disable indexes and Bulk-load data
The best scenario is bulk- loading data into an empty heap ( a table with no indexes )
Disable indexes before Bulk-load and rebuild indexes once the Bulk-Load completed.
2.Bulk-logged Recovery Model
Change recovery mode from FULL to Bulk-Logged lets database perform minimal logging during the data load.
Data that is loaded during a bulk load usually has no need for the point-in-time recovery capability of the full recovery model.
Decreasing the volume of log writes improves performance.
Note: Recovery models - Full [Default Recovery Model] ,
Bulk Logged and
Simple
Sunday, May 23, 2010
SQL Server 2008 Features - Data Tracking Solutions
Data Tracking Solutions
SQL Server 2008 introduces two tracking features that enable applications to determine the DML changes (insert, update, and delete operations) that were made to user tables in a database.
1.Change Data capture
2.Change Tracking
Before these features were available, custom tracking mechanisms had to be implemented in applications.
Elimiates expensive techniques
Using Triggers,timestamp columns, new tables to store tracking information, and custom cleanup processes.
Build a Data Tracking Solution by Change Data capture
Change data capture provides historical change information for a user table by capturing both the fact that DML changes were made and the actual data that was changed
Changes are captured by using an asynchronous process that reads the transaction log and has a low impact on the system
We Can provide answers to a variety of key questions
What are ALL the changes that happened between 12:00AM and 12:00PM?
I want to get a transactional consistent set of all changes that happened in Order table and Order_Detail since 12:00PM
Which column changed?
Was the change an insert or an update?
Implementation
CDC enabled at two levels
Database Level - SP_CDC_ENABLE_DB
Individual tables - SP_CDC_ENABLE_TABLE
USE [MyDataBase]
GO
EXEC sys.sp_cdc_enable_db_change_data_capture
GO
The following CDC tables are created under the CDC schema,
cdc.captured_columns
cdc.change_tables
cdc.ddl_history
cdc.index_columns
cdc.lsn_time_mapping
SQL Server 2008 introduces two tracking features that enable applications to determine the DML changes (insert, update, and delete operations) that were made to user tables in a database.
1.Change Data capture
2.Change Tracking
Before these features were available, custom tracking mechanisms had to be implemented in applications.
Elimiates expensive techniques
Using Triggers,timestamp columns, new tables to store tracking information, and custom cleanup processes.
Build a Data Tracking Solution by Change Data capture
Change data capture provides historical change information for a user table by capturing both the fact that DML changes were made and the actual data that was changed
Changes are captured by using an asynchronous process that reads the transaction log and has a low impact on the system
We Can provide answers to a variety of key questions
What are ALL the changes that happened between 12:00AM and 12:00PM?
I want to get a transactional consistent set of all changes that happened in Order table and Order_Detail since 12:00PM
Which column changed?
Was the change an insert or an update?
Implementation
CDC enabled at two levels
Database Level - SP_CDC_ENABLE_DB
Individual tables - SP_CDC_ENABLE_TABLE
USE [MyDataBase]
GO
EXEC sys.sp_cdc_enable_db_change_data_capture
GO
The following CDC tables are created under the CDC schema,
cdc.captured_columns
cdc.change_tables
cdc.ddl_history
cdc.index_columns
cdc.lsn_time_mapping
Thursday, April 29, 2010
Synonyms
A synonym is an alternate name for a schema scoped object. Synonyms allow client applications to use the single-part name of a synonym to reference a base object instead of a using a two-, three-, or four-part name to reference the base object.
Advantage
It replaces long multi-part object name in SQL Statement
It also provides an abstractions layer which will protect SQL statement using synonyms from changes in underlying objects (tables etc).
Example
-- CREATE SYNONYMS
CREATE SYNONYM MyWork
FOR SQLWorks.dbo.test
-- USE SYNONYMS
SELECT * FROM MyWork
-- DROP SYNONYMS
DROP SYNONYM MyWork
Advantage
It replaces long multi-part object name in SQL Statement
It also provides an abstractions layer which will protect SQL statement using synonyms from changes in underlying objects (tables etc).
Example
-- CREATE SYNONYMS
CREATE SYNONYM MyWork
FOR SQLWorks.dbo.test
-- USE SYNONYMS
SELECT * FROM MyWork
-- DROP SYNONYMS
DROP SYNONYM MyWork
Sunday, April 25, 2010
Ranking Functions #1
Ranking functions return a ranking value for each row in a partition. Depending on the function that is used.Ranking functions are nondeterministic.*
The four ranking functions are ROW_NUMBER(), NTILE(), RANK() and DENSE_RANK() in SQL.
#1 ROW_NUMBER() function
“Returns the sequential number of a row within a partition of a result set, starting at 1 for the first row in each partition.”
Syntax
ROW_NUMBER ( ) OVER ( [ partition_by_clause ] order_by_clause )
[ partition_by_clause ] is optional
partition_by_clause
Divides the result set produced by the FROM clause into partitions to which the ROW_NUMBER function is applied.
order_by_clause
Determines the sequence in which the rows are assigned their unique ROW_NUMBER within a specified partition.
Example
--********** RANKING FUNCTION #1 ROW_NUMBER() ********
-- Create table
CREATE TABLE RankTest (CandidateID int NOT NULL,
[Year] smallint NOT NULL,
Department VARCHAR(100) NOT NULL
);
-- Insert data
INSERT INTO RankTest (CandidateID, [Year], Department)
select 1,2010,'SOFTWARE' UNION ALL select 1,2010,'BIZINFO' UNION ALL
select 1,2010,'ECOMMERCE' UNION ALL select 1,2010,'BIZINFO' UNION ALL
select 1,2010,'ECOMMERCE' UNION ALL select 1,2010,'BIZINFO' UNION ALL
select 1,2010,'ECOMMERCE' UNION ALL select 1,2010,'ECOMMERCE' UNION ALL
select 1,2010,'BIZINFO' UNION ALL select 1,2010,'SOFTWARE' UNION ALL
select 2,2010,'SOFTWARE' UNION ALL select 2,2010,'BIZINFO' UNION ALL
select 2,2010,'ECOMMERCE' UNION ALL select 2,2010,'BIZINFO' UNION ALL
select 2,2010,'ECOMMERCE' UNION ALL select 2,2010,'BIZINFO' UNION ALL
select 2,2010,'ECOMMERCE' UNION ALL select 2,2010,'ECOMMERCE' UNION ALL
select 2,2010,'BIZINFO' UNION ALL select 2,2010,'SOFTWARE';
--ROW_NUMBER() #1
SELECT CandidateID ,[Year] , Department , ROW_NUMBER() OVER (PARTITION BY Department ORDER BY CandidateID)
FROM RankTest
--ROW_NUMBER() #2
SELECT CandidateID ,[Year] , Department , ROW_NUMBER() OVER (ORDER BY Department)
FROM RankTest
The four ranking functions are ROW_NUMBER(), NTILE(), RANK() and DENSE_RANK() in SQL.
#1 ROW_NUMBER() function
“Returns the sequential number of a row within a partition of a result set, starting at 1 for the first row in each partition.”
Syntax
ROW_NUMBER ( ) OVER ( [ partition_by_clause ] order_by_clause )
[ partition_by_clause ] is optional
partition_by_clause
Divides the result set produced by the FROM clause into partitions to which the ROW_NUMBER function is applied.
order_by_clause
Determines the sequence in which the rows are assigned their unique ROW_NUMBER within a specified partition.
Example
--********** RANKING FUNCTION #1 ROW_NUMBER() ********
-- Create table
CREATE TABLE RankTest (CandidateID int NOT NULL,
[Year] smallint NOT NULL,
Department VARCHAR(100) NOT NULL
);
-- Insert data
INSERT INTO RankTest (CandidateID, [Year], Department)
select 1,2010,'SOFTWARE' UNION ALL select 1,2010,'BIZINFO' UNION ALL
select 1,2010,'ECOMMERCE' UNION ALL select 1,2010,'BIZINFO' UNION ALL
select 1,2010,'ECOMMERCE' UNION ALL select 1,2010,'BIZINFO' UNION ALL
select 1,2010,'ECOMMERCE' UNION ALL select 1,2010,'ECOMMERCE' UNION ALL
select 1,2010,'BIZINFO' UNION ALL select 1,2010,'SOFTWARE' UNION ALL
select 2,2010,'SOFTWARE' UNION ALL select 2,2010,'BIZINFO' UNION ALL
select 2,2010,'ECOMMERCE' UNION ALL select 2,2010,'BIZINFO' UNION ALL
select 2,2010,'ECOMMERCE' UNION ALL select 2,2010,'BIZINFO' UNION ALL
select 2,2010,'ECOMMERCE' UNION ALL select 2,2010,'ECOMMERCE' UNION ALL
select 2,2010,'BIZINFO' UNION ALL select 2,2010,'SOFTWARE';
--ROW_NUMBER() #1
SELECT CandidateID ,[Year] , Department , ROW_NUMBER() OVER (PARTITION BY Department ORDER BY CandidateID)
FROM RankTest
--ROW_NUMBER() #2
SELECT CandidateID ,[Year] , Department , ROW_NUMBER() OVER (ORDER BY Department)
FROM RankTest
Thursday, April 22, 2010
NEWID() Function
Creates a unique value of type uniqueidentifier.
We can use this function to randomly sort records in the table
Example
--***** NEWID() *********
SELECT TOP 10 * FROM wages ORDER BY NEWID()
You will get new set records everytime you run the above query
We can use this function to randomly sort records in the table
Example
--***** NEWID() *********
SELECT TOP 10 * FROM wages ORDER BY NEWID()
You will get new set records everytime you run the above query
Wednesday, April 21, 2010
CUBE Operator in TSQL
We can use CUBE operator with GROUP BY clause to summarize data in a table .
Following are the specific differences between CUBE and ROLLUP:
* CUBE generates a result set that shows aggregates for all combinations of values in the selected columns.
* ROLLUP generates a result set that shows aggregates for a hierarchy of values in the selected columns.
If the ROLLUP keyword in the query is changed to CUBE, the CUBE result set is the same, except these two additional rows are returned at the end
Example:
--********* CUBE Operator ***********
SELECT
CASE WHEN GROUPING(CategoryName) = 1 THEN 'ALL Categories' ELSE CategoryName END AS Category_Name ,
CASE WHEN GROUPING(VENDOR) = 1 THEN 'ALL Vendors' ELSE VENDOR END AS Vendor, COUNT(URL) AS URLS
FROM testRoolUp
GROUP BY CategoryName , VENDOR
WITH CUBE

Following are the specific differences between CUBE and ROLLUP:
* CUBE generates a result set that shows aggregates for all combinations of values in the selected columns.
* ROLLUP generates a result set that shows aggregates for a hierarchy of values in the selected columns.
If the ROLLUP keyword in the query is changed to CUBE, the CUBE result set is the same, except these two additional rows are returned at the end
Example:
--********* CUBE Operator ***********
SELECT
CASE WHEN GROUPING(CategoryName) = 1 THEN 'ALL Categories' ELSE CategoryName END AS Category_Name ,
CASE WHEN GROUPING(VENDOR) = 1 THEN 'ALL Vendors' ELSE VENDOR END AS Vendor, COUNT(URL) AS URLS
FROM testRoolUp
GROUP BY CategoryName , VENDOR
WITH CUBE

Tuesday, April 20, 2010
ROLLUP Operator
The ROLLUP operator is useful in generating reports that contain subtotals and totals. For example when we want the report which shows URL Count for each Category and Vendor , simply we can use group by Category and Vendor
SELECT CategoryName ,VENDOR , COUNT(URL) AS URLS
FROM testRoolUp
GROUP BY CategoryName , VENDOR
Output:
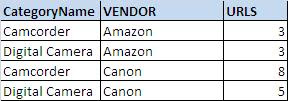
When we want report like below , Here ROLLUP and GROUPING comes into the picture and help us. ROLLUP generates a result set that shows aggregates for a hierarchy of values in the selected columns.
Example
-- *********** ROLLUP ****************
--Create Table
CREATE TABLE testRoolUp
(
CategoryName VARCHAR(100),
Vendor VARCHAR(100),
URL NVARCHAR(MAX)
)
-- Insert data
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Amazon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Amazon', 'http://www.amazon.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Amazon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Amazon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Amazon', 'http://www.amazon.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Amazon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
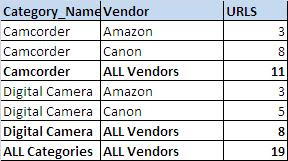
-- ROLLUP
SELECT CategoryName ,VENDOR , COUNT(URL) AS URLS
FROM testRoolUp
GROUP BY CategoryName , VENDOR
WITH ROLLUP
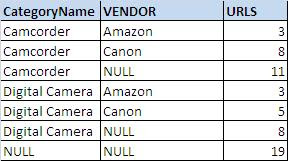
GROUPING clause add new column in result set. The value in new column can either be 0 or 1. If the new row is added by the ROLLUP then the value of GROUPING column is 1 else 0.
-- ROLLUP With GROUPING
SELECT
CASE WHEN GROUPING(CategoryName) = 1 THEN 'ALL Categories' ELSE CategoryName END AS Category_Name ,
CASE WHEN GROUPING(VENDOR) = 1 THEN 'ALL Vendors' ELSE VENDOR END AS Vendor, COUNT(URL) AS URLS
FROM testRoolUp
GROUP BY CategoryName , VENDOR
WITH ROLLUP
SELECT CategoryName ,VENDOR , COUNT(URL) AS URLS
FROM testRoolUp
GROUP BY CategoryName , VENDOR
Output:

When we want report like below , Here ROLLUP and GROUPING comes into the picture and help us. ROLLUP generates a result set that shows aggregates for a hierarchy of values in the selected columns.

Example
-- *********** ROLLUP ****************
--Create Table
CREATE TABLE testRoolUp
(
CategoryName VARCHAR(100),
Vendor VARCHAR(100),
URL NVARCHAR(MAX)
)
-- Insert data
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Amazon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Amazon', 'http://www.amazon.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Amazon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Digital Camera' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Amazon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Amazon', 'http://www.amazon.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Amazon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
INSERT INTO testRoolUp (CategoryName ,Vendor, URL) VALUES ('Camcorder' ,'Canon', 'http://www.shopzilla.com')
-- ROLLUP
SELECT CategoryName ,VENDOR , COUNT(URL) AS URLS
FROM testRoolUp
GROUP BY CategoryName , VENDOR
WITH ROLLUP

GROUPING clause add new column in result set. The value in new column can either be 0 or 1. If the new row is added by the ROLLUP then the value of GROUPING column is 1 else 0.
-- ROLLUP With GROUPING
SELECT
CASE WHEN GROUPING(CategoryName) = 1 THEN 'ALL Categories' ELSE CategoryName END AS Category_Name ,
CASE WHEN GROUPING(VENDOR) = 1 THEN 'ALL Vendors' ELSE VENDOR END AS Vendor, COUNT(URL) AS URLS
FROM testRoolUp
GROUP BY CategoryName , VENDOR
WITH ROLLUP
Monday, April 19, 2010
SET IMPLICIT_TRANSACTIONS
This option is very useful in testing environment , we can test/analyze data by running queries against a table and data can be easily rolled back to the old state.
SET IMPLICIT_TRANSACTIONS ON
When a connection is in implicit transaction mode we must explicitly committed or rolled back. Otherwise, the transaction and all of the data changes it contains are rolled back when the user disconnects.
--*********** Implicit Transaction ON**************
SET IMPLICIT_TRANSACTIONS ON;
UPDATE wages SET hourly_wage = 200
SELECT * FROM wages
ROLLBACK TRANSACTION
[OR]
COMMIT TRANSACTION
When you are not COMMIT/ROLLBACK transaction explicitly , and try to close the connection you will get the following confirmation message box.
We can enable Implicit Transaction using Query options also
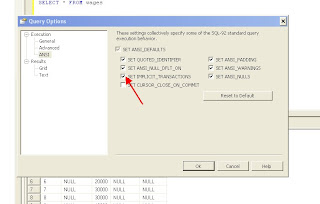
SET IMPLICIT_TRANSACTIONS ON
When a connection is in implicit transaction mode we must explicitly committed or rolled back. Otherwise, the transaction and all of the data changes it contains are rolled back when the user disconnects.
--*********** Implicit Transaction ON**************
SET IMPLICIT_TRANSACTIONS ON;
UPDATE wages SET hourly_wage = 200
SELECT * FROM wages
ROLLBACK TRANSACTION
[OR]
COMMIT TRANSACTION
When you are not COMMIT/ROLLBACK transaction explicitly , and try to close the connection you will get the following confirmation message box.

We can enable Implicit Transaction using Query options also

Sunday, April 18, 2010
Reset Identity Column
Even though we are deleting all the records in a table (which includes Identity column) sql server maintains Identity value.To resolve this problem we can use RESEED option.
DBCC CHECKIDENT (tablename, RESEED, 0)
Note : we can also use truncate table when there is no foreign key relationship
Example
--******** Reset Identity Column Value **********
CREATE TABLE test(id INT IDENTITY, NAME VARCHAR(10))
INSERT INTO test(name ) VALUES('a')
INSERT INTO test(name ) VALUES('a')
INSERT INTO test(name ) VALUES('a')
DELETE FROM test
-- The above statement will delete the record but maintain the identity value.
INSERT INTO test(name) VALUES ('a')
SELECT * FROM test
Output
id name
4 a
DBCC CHECKIDENT (tablename, RESEED, 0)
Note : we can also use truncate table when there is no foreign key relationship
Example
--******** Reset Identity Column Value **********
CREATE TABLE test(id INT IDENTITY, NAME VARCHAR(10))
INSERT INTO test(name ) VALUES('a')
INSERT INTO test(name ) VALUES('a')
INSERT INTO test(name ) VALUES('a')
DELETE FROM test
-- The above statement will delete the record but maintain the identity value.
INSERT INTO test(name) VALUES ('a')
SELECT * FROM test
Output
id name
4 a
Friday, April 16, 2010
Database Snapshot
A database snapshot is a read only copy of our database, but not exactly a copy. Snapshots can be used for auditing & reporting purposes and Recovery.
Useful scenarios
Snapshots can be used in conjunction with database mirroring for reporting purposes. You can create a database snapshots on the mirror database and direct client connection requests to the most recent snapshot.
Maintaining historical data for report generation. You can create a database snapshot at the end of a given time period (such as a financial period) for later reporting.
Safeguarding data against administrative and user error. A database can be reverted back to the state it was in when the snapshot was created. Reverting is potentially much faster for this purpose than restoring from a backup.
In a test environment, it can be useful to quickly return a database back to the state it was prior a test run.
Note: Database snapshots are available only in the Enterprise Edition of Microsoft SQL Server
How Database Snapshots Work?
When the snapshot is first created, the sparse file is empty as shown below. When data is read from the snapshot, it is actually being read from the primary database files. As data changes in your primary database, SQL Server then writes out what the data looked like prior to the data change into a sparse file, so this way the data stays static.
The snapshot will then read the sparse file for the data that has been changed and continue to read the primary database for data that has not changed.

When the first update operation happens, the original data is copied into the sparse file. The database engine then updates the data in the source database.
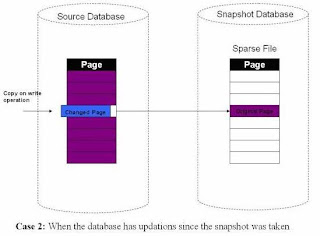
Example
--************ Database Snapshot ************
--1. Create
CREATE DATABASE DB_Snapshot_2009 ON (
NAME = 'test',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\AWDB_Snapshot1.ss')
AS SNAPSHOT OF test; -- database name
--2.Recovery
RESTORE DATABASE test
FROM DATABASE_SNAPSHOT = 'DB_Snapshot_2008'
--3.Drop
Drop database AWDB_Snapshot_20080522
Useful scenarios
Snapshots can be used in conjunction with database mirroring for reporting purposes. You can create a database snapshots on the mirror database and direct client connection requests to the most recent snapshot.
Maintaining historical data for report generation. You can create a database snapshot at the end of a given time period (such as a financial period) for later reporting.
Safeguarding data against administrative and user error. A database can be reverted back to the state it was in when the snapshot was created. Reverting is potentially much faster for this purpose than restoring from a backup.
In a test environment, it can be useful to quickly return a database back to the state it was prior a test run.
Note: Database snapshots are available only in the Enterprise Edition of Microsoft SQL Server
How Database Snapshots Work?
When the snapshot is first created, the sparse file is empty as shown below. When data is read from the snapshot, it is actually being read from the primary database files. As data changes in your primary database, SQL Server then writes out what the data looked like prior to the data change into a sparse file, so this way the data stays static.
The snapshot will then read the sparse file for the data that has been changed and continue to read the primary database for data that has not changed.

When the first update operation happens, the original data is copied into the sparse file. The database engine then updates the data in the source database.

Example
--************ Database Snapshot ************
--1. Create
CREATE DATABASE DB_Snapshot_2009 ON (
NAME = 'test',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\AWDB_Snapshot1.ss')
AS SNAPSHOT OF test; -- database name
--2.Recovery
RESTORE DATABASE test
FROM DATABASE_SNAPSHOT = 'DB_Snapshot_2008'
--3.Drop
Drop database AWDB_Snapshot_20080522
Extract Domain name from URL
The following query extracts domain name from the URL
Example:
URL :http://www.shopzilla.com/sharp-lc46e77u-46-in-1080p-lcd-hdtv/1029258582/compare
Domain : www.shopzilla.com
-- Set Domain_name
update Computers_and_Software
set Domain_Name = a.domain
from
(select Product_URL , replace(substring(Product_URL , 0 , charindex('/' , replace(Product_URL , '//' , '||'))), 'http://' , '') as domain from Computers_and_Software )a
where Computers_and_Software.Product_URL = a.Product_URL
-- Step1
update Computers_and_Software
set Domain_Name = a.domain
from
(
select Product_URL , replace(substring(Product_URL , 0 , charindex('//' , replace(Product_URL , 'http://' , '|||||||'))), 'http://' , '') as domain from Computers_and_Software
where Domain_Name = ' '
) a
where Computers_and_Software.Product_URL = a.Product_URL
--Step2
update Computers_and_Software
set Domain_Name = a.domain
from
(
select Product_URL , replace(substring(Product_URL , 0 , charindex('?' , replace(Product_URL , 'http://' , '|||||||'))), 'http://' , '') as domain from Computers_and_Software
where Domain_Name = ' '
) a
where Computers_and_Software.Product_URL = a.Product_URL
select * from Computers_and_Software
where Domain_Name = ' '
--Step3
update Computers_and_Software
set Domain_Name = Product_URL
where Domain_Name = ' '
Example:
URL :http://www.shopzilla.com/sharp-lc46e77u-46-in-1080p-lcd-hdtv/1029258582/compare
Domain : www.shopzilla.com
-- Set Domain_name
update Computers_and_Software
set Domain_Name = a.domain
from
(select Product_URL , replace(substring(Product_URL , 0 , charindex('/' , replace(Product_URL , '//' , '||'))), 'http://' , '') as domain from Computers_and_Software )a
where Computers_and_Software.Product_URL = a.Product_URL
-- Step1
update Computers_and_Software
set Domain_Name = a.domain
from
(
select Product_URL , replace(substring(Product_URL , 0 , charindex('//' , replace(Product_URL , 'http://' , '|||||||'))), 'http://' , '') as domain from Computers_and_Software
where Domain_Name = ' '
) a
where Computers_and_Software.Product_URL = a.Product_URL
--Step2
update Computers_and_Software
set Domain_Name = a.domain
from
(
select Product_URL , replace(substring(Product_URL , 0 , charindex('?' , replace(Product_URL , 'http://' , '|||||||'))), 'http://' , '') as domain from Computers_and_Software
where Domain_Name = ' '
) a
where Computers_and_Software.Product_URL = a.Product_URL
select * from Computers_and_Software
where Domain_Name = ' '
--Step3
update Computers_and_Software
set Domain_Name = Product_URL
where Domain_Name = ' '
CheckSum Function
Returns the checksum value computed over a row of a table, or over a list of expressions. CHECKSUM is intended for use in building hash indexes.
comparing row (with large size data ex: html source) values in a table can be a difficult and resource intensive process.
Using checksum we can create Hash value for comparison instead of large data
Drawback
If one of the values in the column list changes, the checksum of the list also generally changes. However, there is a chance that the checksum will not change (i.e. collisions ).
So we can use Checksum function when our application can tolerate occasionally missing a change.
Testing
I have tested for Html_source column with 6.5 million data , only less then 100 hash values are wrong but the performance is extraordinary ,
when we need a immediate comparison solution for columns with large data CheckSum function is the best choice
Example
--******* CheckSum Function ***********
-- Generate hash value
ALTER TABLE Compress_Data1
ADD hashvalue AS CHECKSUM(source) PERSISTED
-- Find duplicate using hash value instead of Source
SELECT hashvalue , COUNT(hashvalue) AS Duplicate
FROM Compress_Data1
GROUP BY hashvalue
HAVING COUNT(hashvalue) > 1
comparing row (with large size data ex: html source) values in a table can be a difficult and resource intensive process.
Using checksum we can create Hash value for comparison instead of large data
Drawback
If one of the values in the column list changes, the checksum of the list also generally changes. However, there is a chance that the checksum will not change (i.e. collisions ).
So we can use Checksum function when our application can tolerate occasionally missing a change.
Testing
I have tested for Html_source column with 6.5 million data , only less then 100 hash values are wrong but the performance is extraordinary ,
when we need a immediate comparison solution for columns with large data CheckSum function is the best choice
Example
--******* CheckSum Function ***********
-- Generate hash value
ALTER TABLE Compress_Data1
ADD hashvalue AS CHECKSUM(source) PERSISTED
-- Find duplicate using hash value instead of Source
SELECT hashvalue , COUNT(hashvalue) AS Duplicate
FROM Compress_Data1
GROUP BY hashvalue
HAVING COUNT(hashvalue) > 1
Wednesday, April 14, 2010
COALESCE (T-SQL)
Returns the first nonnull expression among its arguments.If all arguments are NULL, COALESCE returns NULL.
COALESCE(expression1,...n) is equivalent to the following
CASE expression:
CASE
WHEN (expression1 IS NOT NULL) THEN expression1
WHEN (expression2 IS NOT NULL) THEN expression2
...
ELSE expressionN
END
Example
--************ coalesce *******
CREATE TABLE dbo.wages
(
emp_id tinyint identity,
hourly_wage decimal NULL,
salary decimal NULL,
commission decimal NULL,
num_sales tinyint NULL
);
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(10.00, NULL, NULL, NULL),
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(20.00, NULL, NULL, NULL),
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(30.00, NULL, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(40.00, NULL, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, 10000.00, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, 20000.00, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, 30000.00, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, 40000.00, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, NULL, 15000, 3)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, NULL, 25000, 2)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, NULL, 20000, 6)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, NULL, 14000, 4)
SELECT * FROM dbo.wages
SELECT CAST(COALESCE(hourly_wage * 40 * 52, salary, commission * num_sales) AS money) AS 'Total Salary'
FROM dbo.wages
ORDER BY 'Total Salary';
-- using CASE Statement
SELECT CAST(CASE WHEN hourly_wage IS NOT NULL THEN (hourly_wage * 40 * 52)
WHEN salary IS NOT NULL THEN salary
WHEN commission IS NOT NULL AND num_sales IS NOT NULL THEN (commission * num_sales)
END AS MONEY) AS 'Total Salary'
FROM dbo.wages
ORDER BY 'Total Salary';
COALESCE(expression1,...n) is equivalent to the following
CASE expression:
CASE
WHEN (expression1 IS NOT NULL) THEN expression1
WHEN (expression2 IS NOT NULL) THEN expression2
...
ELSE expressionN
END
Example
--************ coalesce *******
CREATE TABLE dbo.wages
(
emp_id tinyint identity,
hourly_wage decimal NULL,
salary decimal NULL,
commission decimal NULL,
num_sales tinyint NULL
);
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(10.00, NULL, NULL, NULL),
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(20.00, NULL, NULL, NULL),
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(30.00, NULL, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(40.00, NULL, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, 10000.00, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, 20000.00, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, 30000.00, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, 40000.00, NULL, NULL)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, NULL, 15000, 3)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, NULL, 25000, 2)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, NULL, 20000, 6)
INSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES(NULL, NULL, 14000, 4)
SELECT * FROM dbo.wages
SELECT CAST(COALESCE(hourly_wage * 40 * 52, salary, commission * num_sales) AS money) AS 'Total Salary'
FROM dbo.wages
ORDER BY 'Total Salary';
-- using CASE Statement
SELECT CAST(CASE WHEN hourly_wage IS NOT NULL THEN (hourly_wage * 40 * 52)
WHEN salary IS NOT NULL THEN salary
WHEN commission IS NOT NULL AND num_sales IS NOT NULL THEN (commission * num_sales)
END AS MONEY) AS 'Total Salary'
FROM dbo.wages
ORDER BY 'Total Salary';
Table Row Count
Many times we need to find out how many rows a particular table has?. Generally Select Count(*) From table query is used for same. It becomes very time consuming if a table is having bulk records.
Here is an another way to find the rows count in table very quickly no matter how many millions rows that table is having:
SELECT object_name(object_id) As TableName ,row_count
FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID('Token_Output');
Note: 'Token_Output' - Table Name
In SQL Server 2008 we have the following option
exec sp_rowcount 'table name'
Here is an another way to find the rows count in table very quickly no matter how many millions rows that table is having:
SELECT object_name(object_id) As TableName ,row_count
FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID('Token_Output');
Note: 'Token_Output' - Table Name
In SQL Server 2008 we have the following option
exec sp_rowcount 'table name'
Subscribe to:
Comments (Atom)
